Boost your query performance using Snowflake Clustering keys
Snowflake, like many other MPP databases, uses micro-partitions to store the data and quickly retrieve it when queried. In Snowflake, the partitioning of the data is called clustering, which is defined by cluster keys you set on a table. The method by which you maintain well-clustered data in a table is called re-clustering (NOTE: Snowflake has recently introduced automatic clustering)
While loading data into a Snowflake table,
- Snowflake splits the data and stores it in micro-partitions in the same order as the data arrives from the source. If possible, It also co-locates column data with the same values in the same micro-partition.
- Snowflake also remembers the total number of micro-partitions that comprise the table
- Snowflake also remembers the number of micro-partitions containing values that overlap with each other (i.e Range of values in each micro-partition for each column)
- and the depth of the overlapping micro-partitions.
While data retrieval,
Snowflake leverages the metadata it maintains for each table and scans only the micro-partitions that have the required data, significantly accelerating the performance of queries that reference these columns
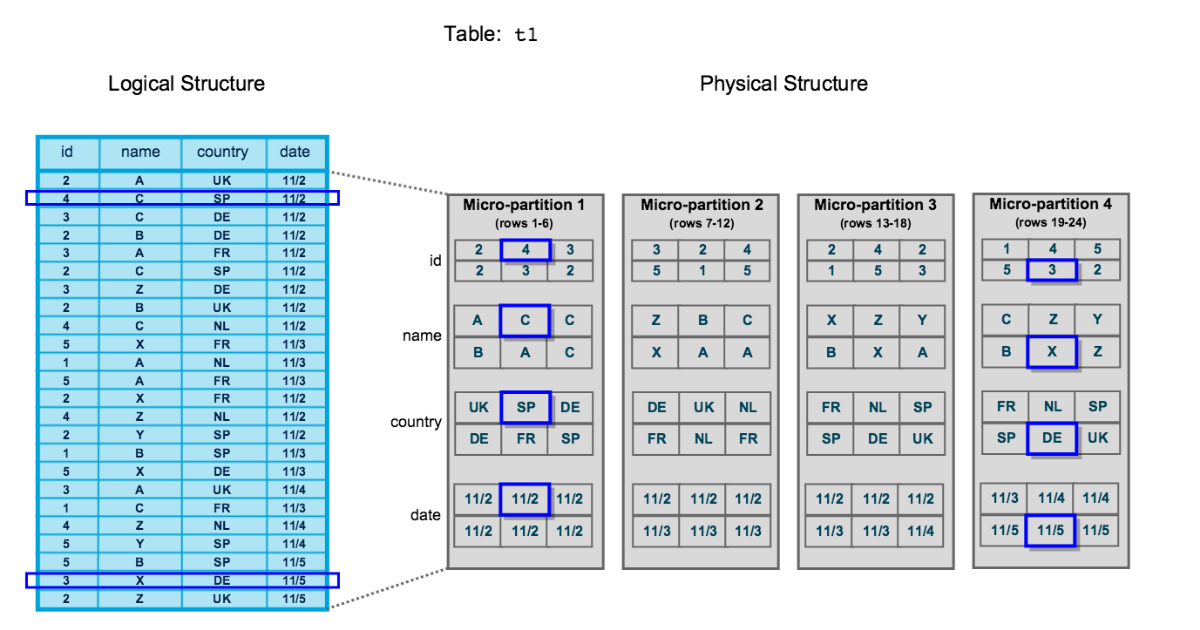
For example, The table consists of 24 rows stored across 4 micro-partitions, with the rows divided equally between each micro-partition. Within each micro-partition, the data is sorted and stored by column, which enables Snowflake to perform the following actions for queries on the table:
- First prune micro-partitions that are not needed for the query
- Then prune by column within the remaining micro-partitions
What are Snowflake Clustering Keys?
Snowflake uses the Cluster keys to sort the data in the tables and then it splits the data into multiple micro-partitions in the same sort order.
Benefits of Clustering
- Queries that use the cluster keys in the where clause will have Improved scan efficiency as they skip a large amount of data that does not match filtering predicates.
- Better column compression than in tables with no clustering keys. This is especially true when other columns are strongly correlated with the clustering keys.
- After the keys have been defined, limited manual maintenance (or no maintenance if Automatic Clustering is enabled for the table)
What happens during a manual reclustering?
For example, if I am doing the below recluster,
ALTER TABLE t1 CLUSTER BY (date,id);
ALTER TABLE t1 RECLUSTER;
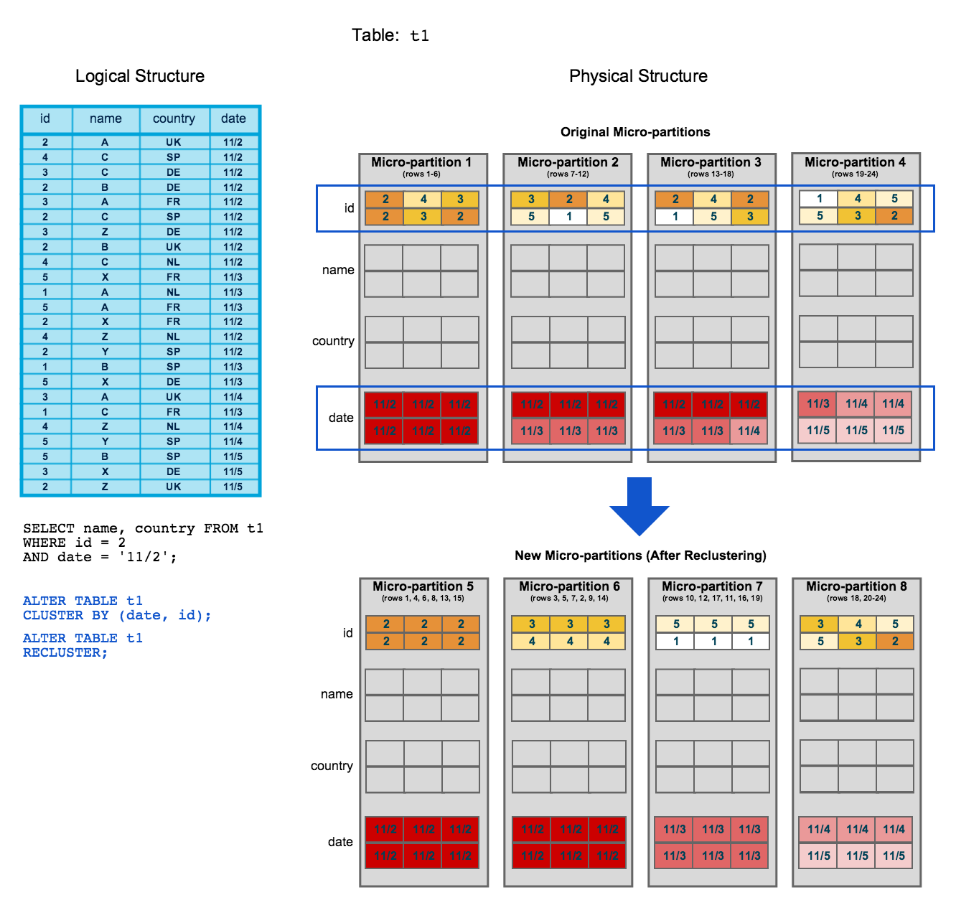
(Image courtesy: Snowflake docs)
How to choose the best Clustering Keys
- The primary methodology for picking cluster keys on your table is to choose fields that are accessed frequently in WHERE clauses.
- If you have two or three tables that share a field on which you frequently join (e.g. user_id) then add this commonly used field as a cluster key on the larger table or all tables.
- If you have a field that you frequently count(distinct) then add it to the cluster keys. Having this field sorted will give Snowflake a leg up and speed up count(distinct) and all other aggregate queries.
- Snowflake is pretty smart about how it organizes the data, so you do not need to be afraid to choose a high cardinality key such a UUID or a timestamp
How often to recluster
Even if you specify a cluster key, snowflake will ignore it unless a "RECLUSTER" command is issued manually, so make a note to recluster your tables frequently if you have a lot of DML's happening on the table. When loading new data make sure you are re-clustering the table after each load. If you are trickle loading, you can separate the load and re-cluster process by re-clustering every several minutes rather than with each load.
NOTE: Snowflake has recently introduced an automatic recluster feature. Where snowflake will recluster the tables on its own in the background. which is a nice feature to make use of
Monitoring Snowflake Cluster health
Snowflake provides two system functions that let you know how well your table is clustered, system$clustering_ratio and system$clustering_information.
system$clustering_ratio provides a number from 0 to 100, where 0 is bad and 100 is great. We found that the ratio is not always a useful number. For example, we had a table that was clustered on some coarse grain keys and then we ended up adding a UUID to the cluster keys. Our clustering ratio went from the high 90s to the 20, yet performance was still great.
select system$clustering_ratio('tbl_a','date,user_id')
where date between '2017-01-01' and '2017-03-01';The clustering_information function returns a JSON document that contains a histogram and is a very rich source of data about the state of your table. Here is an example from one of our tables:
select SYSTEM$CLUSTERING_INFORMATION( 'tbl_a', ' (ID, DATE, EVENT))' );
{
"cluster_by_keys" : "(ID, DATE, EVENT)",
"total_partition_count" : 15125333,
"partition_depth_histogram" : {
"00000" : 0,
"00001" : 13673943,
"00002" : 0,
"00003" : 0,
"00004" : 0,
"00005" : 0,
"00006" : 0,
"00007" : 0,
"00008" : 5,
"00009" : 140,
"00010" : 1460,
"00011" : 9809,
"00012" : 38453,
"00013" : 85490,
"00014" : 133816,
"00015" : 176427,
"00016" : 222834,
"00032" : 782913,
"00064" : 43
}
}- The buckets 00000 through 00064 describe in how many micro-partitions (similar in concept to files) your cluster keys are split into.
- The 00001 bucket means that only one micro-partition contains a certain cluster key (In our concrete example above, the 13 million in the 00001 bucket tells us that 13 million of our micro-partitions fully contain the cluster keys they are responsible for, this is great when a query utilizes one of those cluster keys, Snowflake will be able to quickly find the data resulting in faster query latency)
- The 00064 means that 64 micro-partitions contain a cluster key. 43 micro-partitions contain cluster keys that are also in up to 64 other micro-partitions, which is bad because we'd need to scan all of these micro-partitions completely to find one of those cluster keys.
The goal is to have the histogram buckets be skewed towards the lower numbers. As the higher end of the histogram grows, Snowflake needs to do more I/O to fetch a cluster key, resulting in less efficient queries.
The Key takeaway's
- Choose the cluster keys based on fields that are accessed frequently in WHERE clauses.
- Load data and then manually re-cluster the table over and over again until cluster histogram reaches equilibrium.
- Always monitor the histogram over time to ensure that you are not degrading into higher buckets slowly or if there is an unexpected change in your data composition

victor
posted on 03 Dec 18Enjoy great content like this and a lot more !
Signup for a free account to write a post / comment / upvote posts. Its simple and takes less than 5 seconds
Post Comment